
Dev.J
[CS50] ASCII코드 본문
컴퓨터가 데이터에 대해 수행하는 작업으로, 숫자가 아닌 문자나 다른 것들을 나타내기 위해 하는 일 : 숫자를 알파벳 문자에 대응시키는 것.
ASCII 코드
컴퓨터는 텍스트를 비롯한 다양한 형태의 정보를 저장해야 하지만 컴퓨터가 0과 1로된 데이터만 저장할 수 있기 때문에, 0과 1을 이용해 텍스트 문자로 나타내야 한다. ASCII(아스키)는 문자를 컴퓨터가 이해할 수 있는 이진 데이터(0 또는 1)로, 혹은 그 반대로 변환하는 표준 방법이다.
ASCII 인코딩 표준
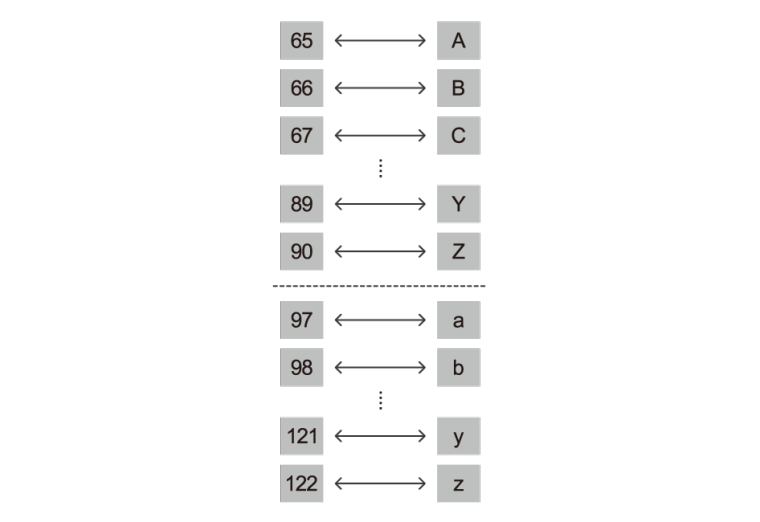
ASCII(아스키)는 컴퓨터가 텍스트 데이터를 저장하기 위해 흔하게 사용하는 표준코드체계이다. 이 표준에서 숫자 65는 대문자 ‘A’와 대응된다. 따라서 컴퓨터가 대문자 ‘A’를 저장하고 싶다면 숫자 65를 이진수로 저장할 것이다(2진수로 나타내면, 1000001). 그 다음의 25개 값들은 다른 대문자 25개와 대응된다.
소문자도 ASCII에서 숫자로 나타낼 수 있다. 소문자 ‘a’는 숫자 97로 나타내고 ‘b’는 98로 나타내며 이 후 다른 소문자들도 마찬가지이다. 따라서 컴퓨터가 소문자 ‘a’를 저장하려면 숫자 97을 2진수, 1100001로 저장해야 한다.
여기서 소문자 ‘a’와 대문자 ‘A’가 2^5의 자릿수만 다르다.
ASCII에서 소문자는 같은 대문자 글자보다 항상 2^5만큼 크다. 결과적으로 이진수에서 2^5의 자릿수만 바꾸면 되기 때문에(소문자는 1, 대문자는 0으로) 소문자와 대문자 간의 변환이 쉬워진다.
ASCII의 한계
흔히 ASCII 코드는 ASCII 코드 표로 나타낸다. ASCII 코드 표는 모든 ASCII 코드 문자와 그에 대응하는 숫자를 보여준다.
기본 ASCII 코드 표는 7비트만 이용해서 모든 문자들을 나타낼 수 있다. 이것은 ASCII 코드로 2^7 개, 즉 128개의 문자를 나타낼 수 있다는 것을 의미한다. 확장 ASCII는 8번째 비트를 추가하여 총 256개의 문자를 나타낼 수 있도록 한다. 소문자와 대문자 통틀어 52개 알파벳 밖에 없으므로, 그 외 남는 공간에 구분 기호, 숫자, 몇몇 기본 심볼들($나 % 기호 등) 같은 다른 종류의 문자들을 나타낼 수 있다.
하지만 8비트 ASCII 코드로도 나타낼 수 없는 문자들이 아직도 많다. 우리가 사용할 수 있는 문자들의 개수는 256개보다 많기 때문이다. 예를 들어, 수학 기호들과 영어 외 다른 언어의 글자들은 표준 ASCII 표에 들어가기 힘들다. 이 때문에 훨씬 더 많은 문자들을 포함할 수 있는 유니코드(Unicode)이 생기게 되었다. 예를 들어, 유니코드는 100만개 이상의 문자들을 나타낼 수 있는 문자 인코딩 표준이다. 이러한 유니코드의 첫 128개의 문자는 ASCII의 128개의 문자와 동일하므로 서로 호환이 된다.
information source : edwith
'Computer Science' 카테고리의 다른 글
| [CS50] 알고리즘 (0) | 2022.03.25 |
|---|---|
| [CS50] 인공지능 (0) | 2022.03.25 |
| [CS50] 가상 현실과 증강 현실 (0) | 2022.03.12 |
| [CS50] 이미지 (0) | 2022.03.12 |
| [CS50] 2진수 (0) | 2022.03.10 |



